Towards Video World Models
The term "world model" has gained considerable popularity in 2025, yet it remains without a clear, universally agreed-upon definition. In this blog post, I will first disentangle the term by clarifying distinct paradigms that are all commonly referred to as world models. I will then focus specifically on video world models, a particular class of world models aimed at simulating the world through video prediction methods. Additionally, I will discuss why popular video generators (e.g., OpenAI’s Sora or Google's Veo3) do not yet qualify as true world models, and outline a path toward bridging this gap within video generation frameworks.
What Are World Models?
Understanding versus Simulating the World
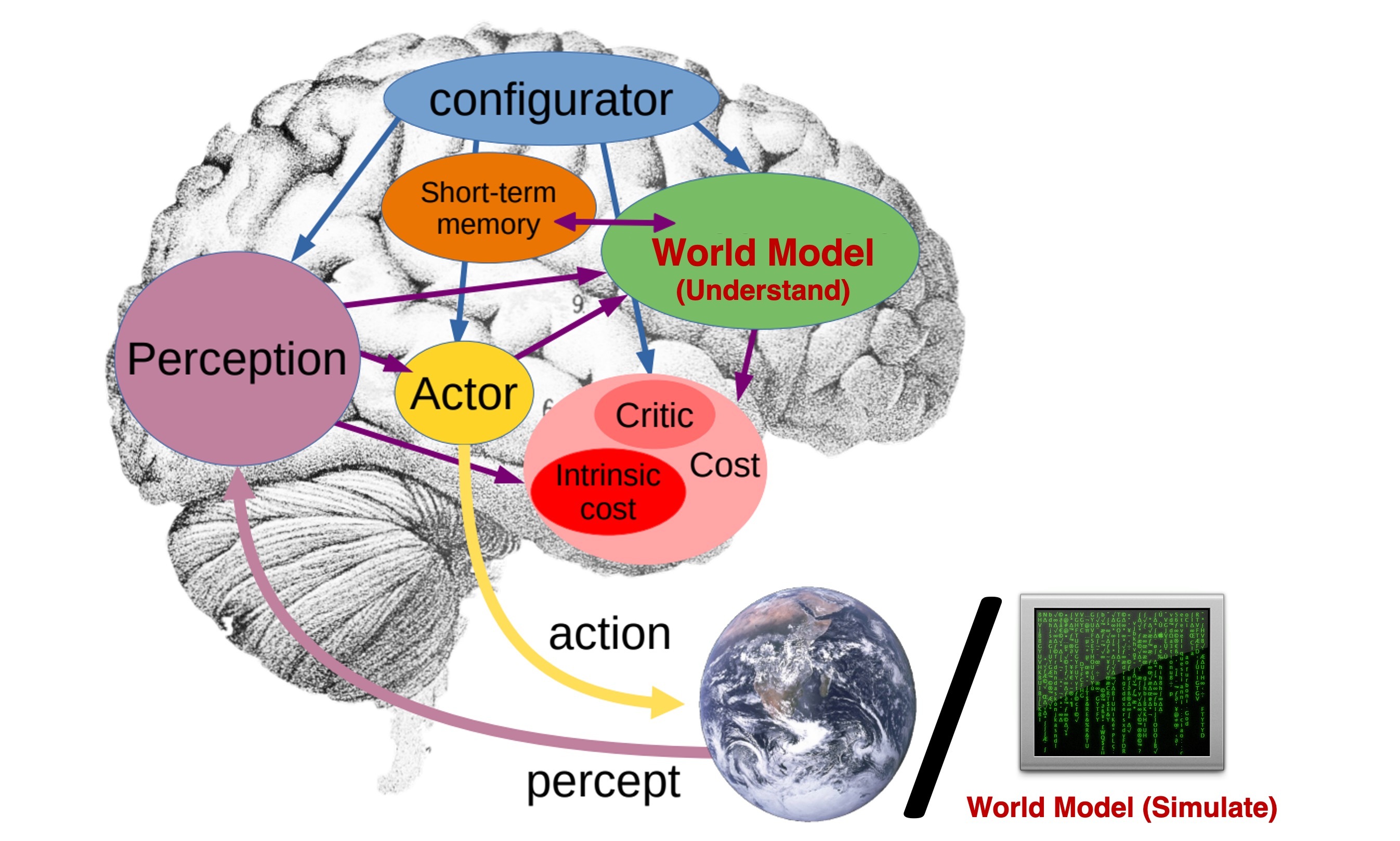
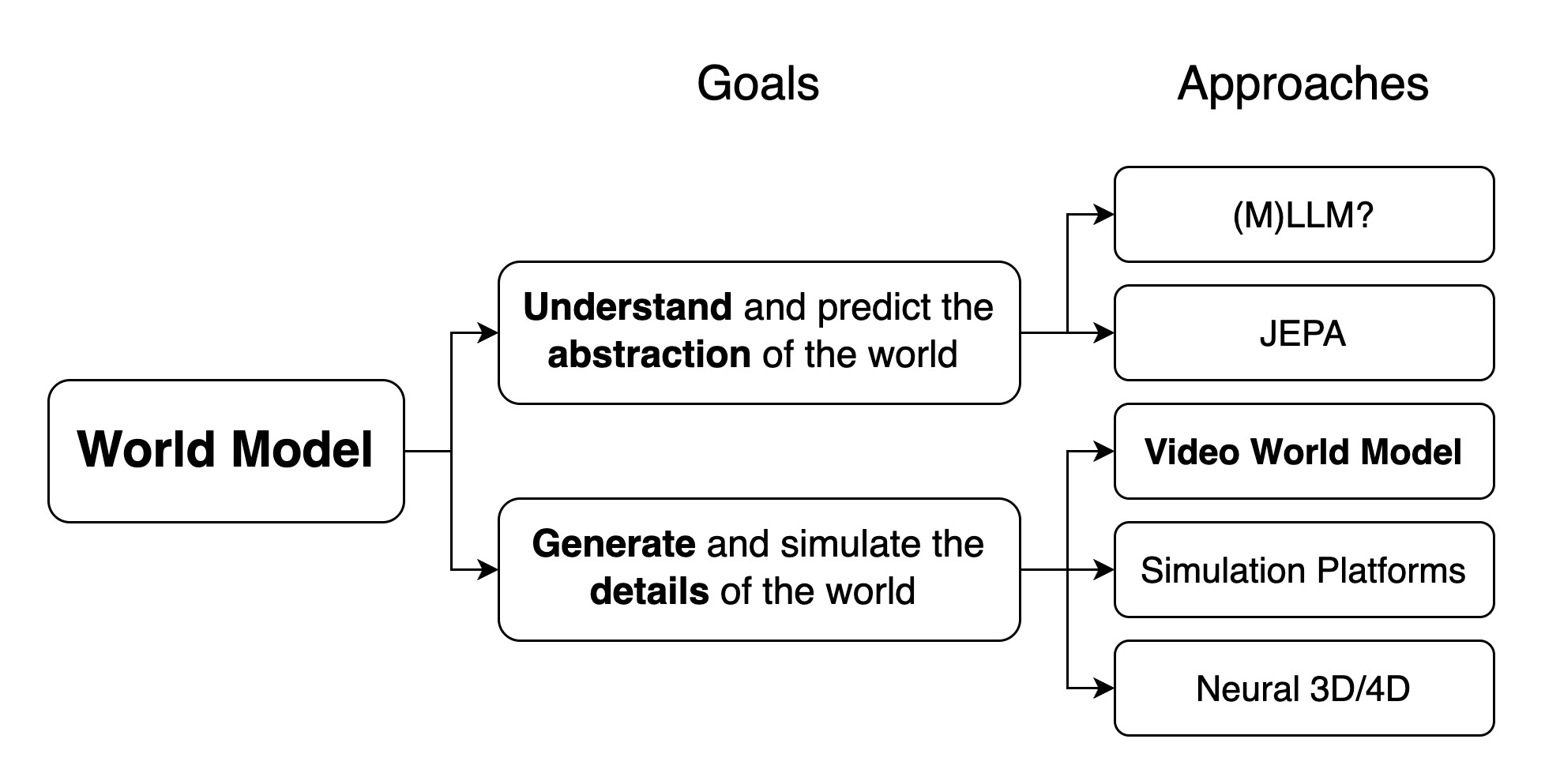
In general, a world model predicts how the world will evolve given the current state and an action; in other words, it learns a function that takes a current world state and an action, and outputs the next state. However, there is no consensus on what constitutes this state. Some researchers define it as an abstract representation of the world, in which case the world model mirrors the cognitive world model in the human brain that predict events at a high, semantic level. Others, on the other hand, consider the world state to be a detailed and complete description of the world. In that case, the world model is a fully realistic world simulator, akin to The Matrix—a high-fidelity simulation virtually indistinguishable from reality. Despite their differing goals and methodologies, both paradigms are commonly referred to as "world models."
The first type of world model requires architectures that internalize world knowledge and perform reasoning and prediction in a semantic space. While LLMs are regarded as a promising path, many argue that its sole reliance on textual knowledge leaves critical gaps in their grasp of reality. A truly grounded world model must go beyond text and engage with the world through vision, action, and interaction. Recent multimodal models like LWM, which are trained on long-context text and video, show promise in this direction. Similarly, LeCun’s JEPA series (e.g., V-JEPA 2) advances this goal by predicting masked abstract video representations.
While simulating pixel-level details may not be essential for intelligence—as LeCun has argued—there remain many applications that require high-fidelity world simulators. Realistic simulations enable robots to learn complex tasks without the cost and limitations of real-world interaction, and they can also provide human users with immersive, interactive experiences. In both cases, high-quality visuals are crucial: robots need detailed visual inputs to bridge the sim-to-real gap, while humans need realistic visuals to experience true immersion. In robotic learning, internal world understanding models and external simulation models can work together—robots can plan and act using internal world models that are learned through interaction with external world models that simulate the environment.
Several approaches exist for building high-fidelity world simulators, including video world models, physics-based simulation platforms, and neural 3D/4D modeling techniques. In the following section, I will focus on video world models and outline a pathway from the current state-of-the-art video generation systems toward true world models.
Video World Models
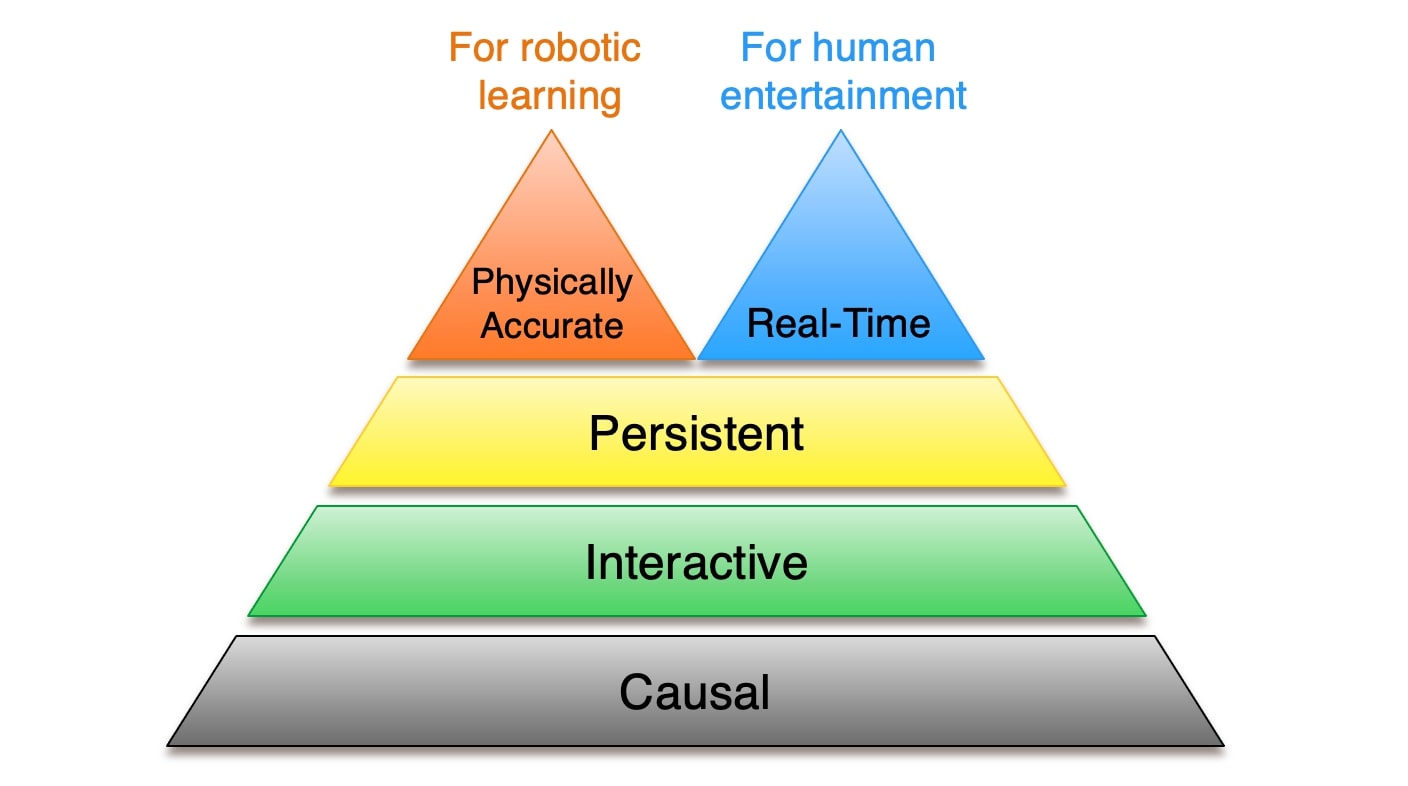
The past few years have seen significant progress in video generation, with state-of-the-art systems now capable of generating photorealistic details with physically realistic dynamics (such as Veo3 from Google). Demis Hassabis, CEO of Google DeepMind, hinted at the potential for developing an interactive world model with applications in gaming by leveraging video generation.But why aren't current video generation models considered true world models yet? What precisely is lacking, and how can we bridge this gap? I argue that a true video world model must be causal, interactive, persistent, real-time, and physical accurate. In the following sections, I examine each property in detail, highlighting its importance and reviewing relevant research.
Causal
Causality + is a fundamental property of the universe. However, state-of-the-art video generation models predominantly employ diffusion transformers (DiTs), which generate a fixed set of frames simultaneously using non-causal, bidirectional attention. Such bidirectional attention allows future frame information to influence the past, violating the inherent temporal asymmetry of reality. As a result, after generating the initial frame, the entire video sequence becomes predetermined, eliminating the possibility for users to dynamically interact or influence subsequent events.
Bringing causal dependencies and autoregressive, frame-by-frame generation capabilities to video generation systems is a first step towards true world models. Without it, real-time interaction is impossible. While LLM-style autoregressive models are inherently causal and have been applied to video generation, e.g., CogVideo and VideoPoet, their quality is severely limited due to the reliance on lossy vector quantization to obtain a discrete latent space. Also, generating one token at a time is slow and cannot be easily parallelized, making it very challenging to achieve real-time speed.
It would be great if we can combine the quality/speed of diffusion models with the causality of autoregressive models. Diffusion Forcing demonstrates that training diffusion models with per-frame independent noise levels enables autoregressive generation capabilities. Although Chen et al. primarily experiment with simple RNN architectures trained on synthetic datasets, CausVid shows that video diffusion transformers with bidirectional attention pretrained on internet-scale video datasets can be successfully adapted into autoregressive diffusion transformers (AR-DiT) with causal attention. MAGI-1 explores pretraining such AR-DiTs from scratch and proposes several infrastructure improvements designed for this type of architecture.
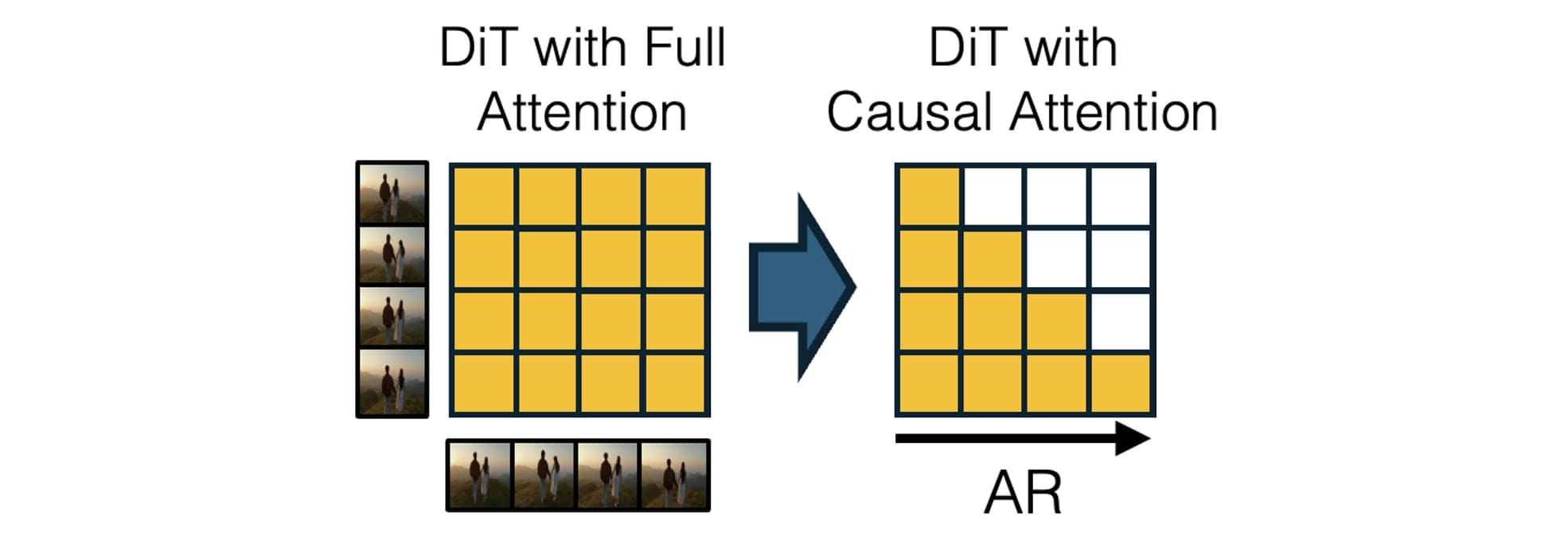
A causal generative model without interactive controllability is a passive world simulator operating in observer mode. To be genuinely useful in practice, a world model must support interactive controls, enabling real-time user or agent engagement with the simulated environment.
Interactive
Interactive controllability is a defining characteristic for video world models. It refers to the ability to influence the future through actions that are injected on the fly.. The nature of actions differs across applications: a gamer might move characters and manipulate objects, a robot must execute motor commands supported by the hardware, while an autonomous vehicle makes steering and acceleration decisions. What unites these diverse scenarios is the fundamental requirement that the world model must respond dynamically to external interventions, adapting its predictions as new actions are introduced.
Early approaches primarily explored game action controls and commonly employed recurrent variational autoencoders as generative world models (Ha and Schmidhuber 2018; Hafner et al., 2020; Hafner et al., 2021). More recently, research has shifted towards (autoregressive) diffusion models conditioned on interactive actions (Valevski et al., 2024; Alonso et al., 2024), often trained on increasingly realistic game environments (Feng et al., 2024; Che et al., 2025; Li et al., 2025). Other forms of application-specific action spaces have also been investigated, such as driving maneuvers in autonomous vehicles (Hu et al., 2023) and locomotion actions in navigation robots (Bar et al., 2025).
A central challenge in enabling interactive controllability is acquiring training data that aligns video frames with corresponding actions. While annotated data can be sourced from gaming environments, leveraging unlabeled, internet-scale video for training interactive world models remains an open problem. Genie explored unsupervised action learning from unlabeled videos, and its successor, Genie-2 showed impressive results by leveraging AR-DiT architecture.
Persistent
Generating just a few seconds of video is insufficient for most applications of world simulation. Ideally, a video world model should be capable of producing videos of indefinite length—or at the very least, videos long enough to support meaningful tasks. More critically, the model must ensure consistency across time, maintaining coherence with its own prior generations. This property, which I refer to as persistence, is another essential requirement for video world models.
At first glance, generating long, consistent videos might appear to be merely a scaling problem: in theory, a transformer with an extremely long context window, trained on sufficiently long-duration data, should be capable of maintaining temporal coherence. However, another critical requirement of a world model—real-time responsiveness (which I will discuss shortly)—complicates the issue. Unlike LLM applications where users can tolerate increased inference time as the context window grows, video world models face a hard latency constraint. For interactive applications such as games, it is unacceptable for the system to slow down over time. A world model that becomes increasingly laggy over time would make the experience unplayable.
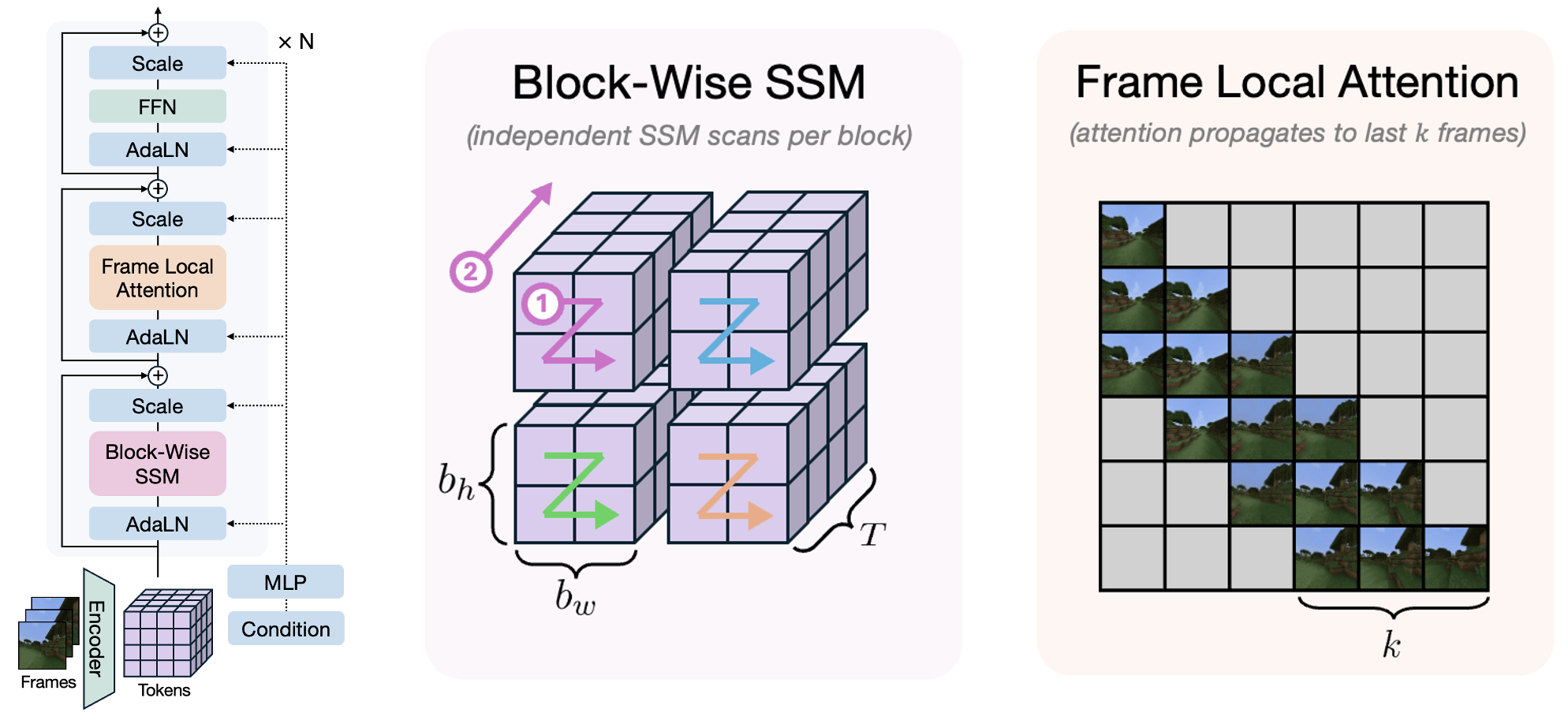
Researchers have proposed various techniques to address this challenge. One common strategy introduces an inductive bias that aggressively compresses temporally distant frames, as in FAR and FramePack. While it works well for scenarios where the recent frames contain sufficient information for prediction, it might fail when crucial details are buried in earlier frames—resembling the "needle in a haystack" problem in LLMs. Another line of work integrates video generation with persistent 3D conditions (Ren et al., 2025, Zhang et al., 2025, Wu et al., 2025, Zhou et al., 2024). While effective in static scenes, these approaches struggle to model dynamic environments due to the complexity of representing explicit 4D structures. Finally, a promising direction is to use a linear RNNs, such as state-space models to capture long-range temporal dependencies without increasing per-frame generation time, as first explored by Po et al., 2025. Their approach integrates a linear RNN with 3D hidden states and incorporates local attention mechanisms, which is reminiscent of classic ConvLSTM architectures widely used for video prediction in the pre-transformer era.
Real-Time
A video world model that aims to provide interactive experience for human users needs to run in real-time, but what exactly does "real-time" mean in this context? To assess whether a model operates in real-time, two metrics need to be considered: throughput and latency. Throughput refers to the number of frames generated per second by the model, while latency is the delay between each interactive action and the frame that responds to it. Achieving real-time throughput—where the model generates frames at or above the rate that users consume them—is a necessary condition for delivering a real-time experience.
However, real-time throughput is not sufficient. The latency of the model must also be low enough to be imperceptible to the user. The latency generally needs to be less than a second, and the specific latency threshold varies across applications. For example, studies have showed that the acceptable latency is about one second for live streaming, 0.1s for gaming, and 0.01s for virtual reality. And here is another reason why causal/autoregressive generation is so fundamental to video world models: a model with non-causal dependencies that generates a t-second video at a time has a minimum latency of t seconds in response to frame-wise interactive actions. Therefore, a non-causal diffusion model will never achieve truly real-time latency, regardless of how fast throughput the model can achieve.
To enable real-time experience, it's crucial to integrate causal, frame-by-frame autoregressive modeling with a fast, few-step distilled diffusion process to generate each frame. CausVid was a pioneer in this direction, introducing AR-DiT trained with Distribution Matching Distillation (DMD). The follow-up work, Self-Forcing, further improves the quality and speed by simulating the inference process (autoregressive rollout with KV caching) during training. It achieves real-time throughput (17FPS) and subsecond latency on a single GPU, while matching the quality of state-of-the-art open-source video diffusion models. APT2 explores a similar idea of training-time rollout, and further demonstrates that such real-time video models can be finetuned with interactive controls. There have also been demos from startups such as Decart, Odyssey, Wayfarer Labs and Dynamics Lab, though overall the quality and generalizability still lag behind state-of-the-art video generation models.
Physically Accurate
The ultimate goal of video world models is to serve as a world simulator that is indistinguishable from reality. This requires the model not only to generate visually pleasing pixels, but also to adhere to real-world physics. While the physical realism of these models generally improves as they are scaled with more data and parameters, it remains unclear whether current models can truly learn generalizable and extrapolative physical laws. Kang et al. introduce a simple 2D dataset generated via a physics simulator and evaluate the generalization capabilities of video models trained on this data. They find that although combinatorial generalization is achievable, existing models still fail to generalize in extrapolative scenarios where the observed physical properties (e.g., velocity, mass) are out of distribution.
While this result seems to suggest a doomed future, it doesn’t mean video world models can’t effectively simulate the world in most practical scenarios. Unless you're trying to model cutting-edge physics experiments, the use cases are likely going to be compositionally similar to those found in large internet-scale video datasets. After all, if the training distribution covers the entire world, there is nothing out of distribution. 😉

Beyond simply scaling up models, several techniques have been proposed to enhance the physical realism of video world models. VideoJAM argues that the commonly used pixel reconstruction objective in diffusion models is insufficient for capturing physical coherence. To address this, it introduces a joint training approach that incorporates an additional optical flow denoising objective. Another approach is dataset curation to emphasize rare, out-of-distribution events where physical accuracy is more important. For instance, Ctrl-Crash fine-tunes a video diffusion model on car accident footage, while PISA finetunes it on synthetic or real-world object dropping videos.
Summary
I’ve outlined five key properties of video world models: causality, interactivity, persistence, real-time responsiveness, and physical accuracy, roughly in the order from most fundamental to most challenging. The first two—causality and interactivity—are hard constraints. A world model has to be causal and interactive, while causality is more fundamental, being the prerequisite for interactive controllability. Persistence is a soft constraint, existing on a spectrum; while the ideal world model needs to produce infinitely-long and fully consistent videos, even moderately persistent models are valuable in many applications. There are trade-offs between real-time responsiveness and physical accuracy, the two remaining properties: larger models tend to be more physically accurate but slower, while smaller models are necessary for real-time responsiveness but less physically accurate. I expect different applications of world modeling will prioritize one over the other. For human entertainment, real-time responsiveness is essential and physical accuracy only needs to be good enough to fool human eyes. For robotic learning, physical accuracy is the most important, while real-time simulation during model training is not truly necessary.
Other Approaches to World Simulation
Video world models provide a promising new way to simulate the world, yet they are only one path. Conventional simulators couple a physics engine for dynamics with a renderer for imagery; platforms such as MuJoCo, Isaac, and Genesis plug neatly into robotics-learning pipelines. Still, creating realistic scenes and task-specific worlds in these engines often involves substantial manual effort and limits flexibility. Recent works start to explore automated environment generation with LLM agents, potentially enabling rapid, on-demand creation of new scenarios.
Another approach of world modeling is to use a neural network to generate explicit 3D/4D world representations such as 3D/4D Gaussian Splatting. Latest research in this space includes Wonderland, WonderWorld, Bolt3D, and many others. Startup companies such as World Labs and SpAItial also appear to have works on this direction.
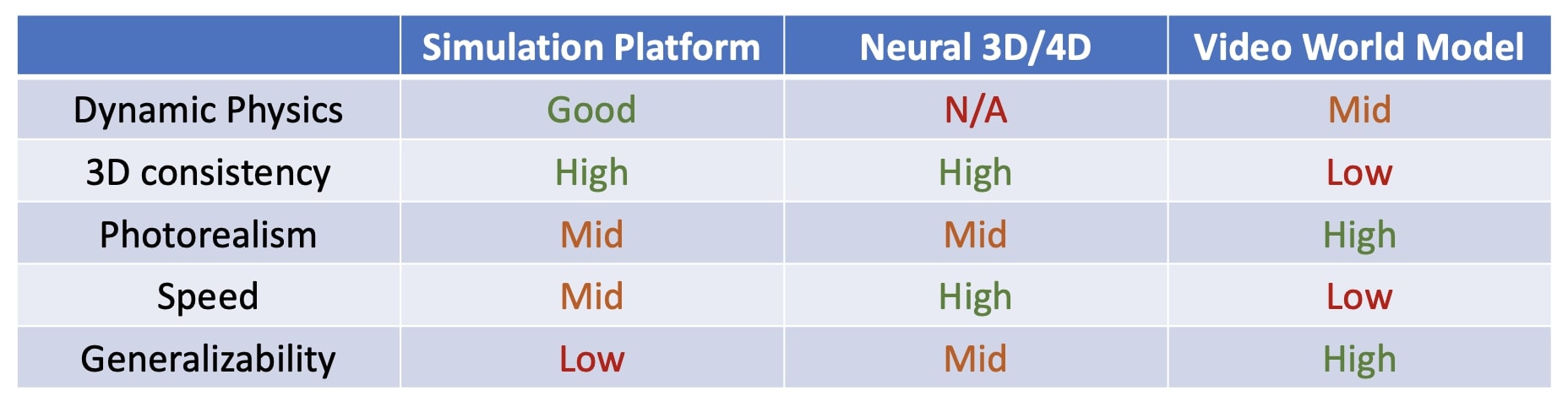
Different approaches offer distinct strengths and limitations. Physics-based simulators are more effective at producing consistent and physically realistic results, but they often require manual effort to design task-specific scenarios. Moreover, traditional rendering pipelines can struggle to deliver full photorealism within real-time computational constraints. Neural 3D methods generate 3D-consistent representations that are fast to render, yet they typically face challenges in modeling dynamic scenes. Meanwhile, video-based world models are highly adaptable to custom needs and capable of producing visually stunning, photorealistic outputs. However, achieving 3D consistency alongside real-time rendering—what I previously referred to as the challenge of "persistence" and "real-time"—remains an open problem. In short term, it might be fruitful to develop hybrid models that combine the strengths of different paradigms. For example, WonderPlay combines physics-based simulators, 3D Gaussian representations, and video diffusion models together to produce photorealistic worlds with physically accurate dynamics.
Disclaimer: The author is not an expert in physics-based simulation or neural rendering. Please take my opinions here with a grain of salt.
Conclusion
The term world model is overloaded: it can describe abstract models predicting high-level outcomes or detailed simulations indistinguishable from reality. In this blog post, I focus on the second definition, outlining the key properties required to transition from video generation to genuine video world modeling. This is an exciting time, as interactive media powered by world models promises to become the next frontier in content creation (following image and video generation), alongside transformative new paradigms in robotic learning enabled by world models.
Citation
If you find this blog post useful, please consider citing:
title={Towards Video World Models},
author={Huang, Xun},
year={2025},
url={https://www.xunhuang.me/blogs/world_model.html}
}
Acknowledgements
I would like to thank Hong-Xing Yu and Beidi Chen for their valuable feedback.
References
- Alonso et al., 2024, Diffusion for World Modeling: Visual Details Matter in Atari
- Assran et al., 2025, V‑JEPA 2: Video World Model Benchmarks
- Bar et al., 2025, Navigation World Models
- Bruce et al., 2024, Genie: Generative Interactive Environments
- Che et al., 2025, GameGen‑X: Interactive Open‑world Game Video Generation
- Chefer et al., 2025, VideoJAM: Joint Appearance‑Motion Representations for Enhanced Video Generation
- Chen et al., 2024, Diffusion Forcing: Next‑token Prediction Meets Full‑Sequence Diffusion
- Feng et al., 2024, The Matrix: Infinite‑Horizon World Generation with Real‑Time Moving Control
- Gosselin et al., 2025, Ctrl‑Crash: Controllable Diffusion for Realistic Car Crashes
- Gu et al., 2025, Long‑Context Autoregressive Video Modeling with Next‑Frame Prediction
- Ha et al., 2018, Recurrent World Models Facilitate Policy Evolution
- Hafner et al., 2020, Dream to Control: Learning Behaviors by Latent Imagination
- Hafner et al., 2021, Mastering Atari with Discrete World Models
- Hong et al., 2022, CogVideo: Large‑Scale Pre‑Training for Text‑to‑Video Generation
- Hu et al., 2023, GAIA‑1: A Generative World Model for Autonomous Driving
- Huang et al., 2025, Self‑Forcing: Bridging the Train‑Test Gap in Autoregressive Video Diffusion
- Kang et al., 2024, How Far Is Video Generation from World Model? A Physical‑Law Perspective
- Kondratyuk et al., 2023, VideoPoet: A Simple Modeling Method for High‑Quality Video Generation
- Li et al., 2025, Hunyuan‑GameCraft: High‑Dynamic Interactive Game Video Generation with Hybrid History Condition
- Li et al., 2025, WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions
- Li et al., 2025, Pisa Experiments: Exploring Physics Post-Training for Video Diffusion Models by Watching Stuff Drop
- Liang et al., 2025, Wonderland: Navigating 3D Scenes from a Single Image
- Lin et al., 2025, Autoregressive Adversarial Post‑Training for Real‑Time Interactive Video Generation
- Liu et al., 2024, World Model on Million‑Length Video and Language with Blockwise RingAttention
- Parker‑Holder et al., 2025, Genie‑2: A Large‑Scale Foundation World Model
- Po et al., 2025, Long‑Context State‑Space Video World Models
- Ren et al., 2025, GEN3C: 3D‑Informed World‑Consistent Video Generation with Precise Camera Control
- Szymanowicz et al., 2025, Bolt3D: Generating 3D Scenes in Seconds
- Teng et al., 2025, MAGI‑1: Autoregressive Video Generation at Scale
- Valevski et al., 2024, Diffusion Models Are Real‑Time Game Engines
- Wu et al., 2025, Video World Models with Long‑term Spatial Memory
- Yin et al., 2024, One‑Step Diffusion with Distribution Matching Distillation
- Yin et al., 2025, From Slow Bidirectional to Fast Autoregressive Video Diffusion Models
- Yu et al., 2024, WonderWorld: Interactive 3D Scene Generation from a Single Image
- Zhang et al., 2024, World‑Consistent Video Diffusion with Explicit 3D Modeling
- Zhang et al., 2025, Packing Input Frame Context in Next‑Frame Prediction Models for Video Generation
- Zhou et al., 2025, Learning 3D Persistent Embodied World Models